
Countless data is already slumbering in companies, if there is a big data strategy or not. In almost every production company, data on articles, workplaces and workplans are managed via ERP systems in order to control production.
Often this data is only used for this specific purpose. This is a pity. This information offers the ideal starting point for the constant optimization of processes that may is necessary today.
There are various ways to get ideas for optimizations. One way is to organize specialist workshops with people from different departments. This is a good opportunity for developing ideas. If the workshop gets out a number of ideas, a dilemma arises. Which idea promises the highest goal achievement?
A utility analysis does not help, if the idea itself is not examined for its probability of success. However, verification is usually not done at all or directly in live production. This is complex, expensive and disrupts the active production flow.
Today there are many ways to virtually redesign production flows and to review new ideas and processes. One is a simulation system.
Nevertheless, simulation systems are usually only available in larger companies and in the automotive sector. This is not only due to the cost of a simulation system. Commercial products cost over EUR 10,000. The necessary expert knowledge is also an obstacle to investing. If you don’t use the knowledge regularly, it is quickly lost.
Is there a production simulation without expert knowledge?
Many of the basic questions of optimizations in production are similar. How does the production order change the lead time of the products? What is the correct lot size for a production order? Where and at what time are bottleneck jobs created? How big must be the buffer for push production in front of the workplace? Does a change to a pull strategy a better job?
How can such questions be answered based on facts for different production situations? And without being a simulation expert for special software. Or you invest in expensive software that is rarely used.
Is it possible to create a simple simulation system self-coded to provide answers to exactly these questions? I answer this question in this blog article and the Simple Production Simulation project developed from it .
Conception of your self-coded (simple) production simulation system
A simulation always starts with a specific question, i.e. with a real problem! That is why it is one of the deadly sins of simulation (according to Liebl) .
- Wrong definition of the study goal
- Deficient involvement of the sponsor
- Unbalanced mixture of core competences
- Inadequate level of detail
- Selection of the wrong simulation tool
- Insufficient validation
- Poor result presentation.
A simulation will never give a solution to the problem directly. But it can and should show possible fact-based optimization approaches that can then be simulated again.
That is why the draft phase begins with the design of the simulation system.
Unlike a professional system, which can be used very flexibly in many different simulation environments, this is also the most important question in a self-programmed system. Because the basic process is not flexible, but „hard-coded“.
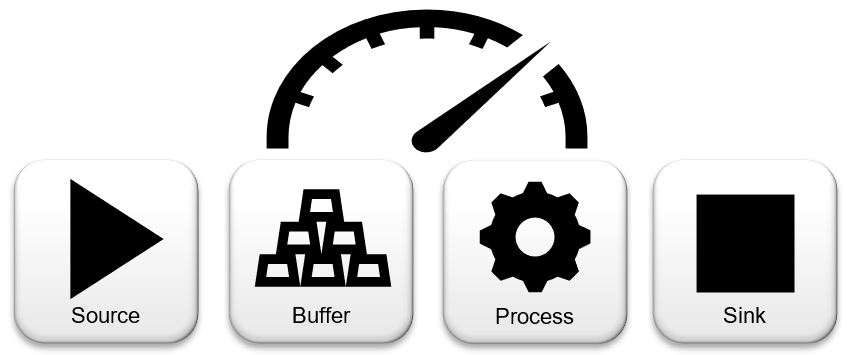
My system maps a specific production environment in which products are manufactured by workplaces. Material flows from a source via buffers to processes and finally to a sink.
Discrete or continuous
Most simulations are based on discrete, event-driven simulation environments. The simulation software only calculates the times when something really happens. The software simply skips the other phases in the timeline, thereby saving simulation time.
In terms of programming, this can be achieved using a chain of events, but at the same time it is a complicated variant. That’s why my simple simulation is based on a continuous simulation – there are no time jumps in the simulation. The smallest unit is one second and every second is run through in the simulation.
Elements of the simulation
In professional systems, the individual elements such as source, buffer, workplaces and sink are modeled and connected to each other according to the production flows.
The starting point of the simulation is a source. In my case, it is the production program and defines the production sequence and quantities of the articles (= products) to be produced.
The articles to be produced are manufactured using individual processes. Processes are carried out in one workplace. Each workplace has an input and output buffer, which can store production orders in a queue.
In professional simulation environments, these material flows are modeled manually by the planner via connections. In my simulation, the connections from the production orders are already known and workplaces are automatically connected to each other.
At the end of the simulation there is a sink, which receives the articles produced and enables evaluations.
Inside the process
The steps within a production order, the work operations, are defined via workplans.
Note: An ERP system is usually not linked to a workplan, but rather a copy of it as a production plan. To simplify the terminology, I use the term workplan here.

The workplan controls the order in which the workplaces must be run through in order to manufacture a product. It defines times for setting up the workplace for the respective production order and the processing times.
| Operation | Workplace | Setuptime | Processtime | |
|---|---|---|---|---|
| 10 | saw | 0 sec | 45 sec | |
| 20 | lathe | 180 sec | 250 sec | |
| … |
The behavior of this system is to be “calculated” with the simulation. This task is represented by a mathematical model. The simulation is intended to calculate the behavior of this system. In this case, the mathematical model is the predictable total order time. It consists of the setuptime and the operating time, the processtime multiplied by the order quantity.

The waittime before and after processing cannot be determined directly. It arises from the length of the queue before and after the workplace. It is calculated for all elements during the simulation and can be evaluated at the end of the simulation.
What simulation cannot do
In the context of the simulation, one thing is, among other things, to capture sections of reality as precisely as possible and as briefly as necessary in a model and then to examine its properties.
J. Biethahn, A. Lackner, M. Range: Optimization and simulation according to P. Mertens
I also follow this approach. The larger the simulation model, the greater the effort and the complexity of the programming increases disproportionately. In order not to make the software environment too large, the time for transports is not taken into account in this variant.
After processing at one workstation, a completed production order is immediately available to the next workstation.
Be it directly for the following processing or in addition to the waiting list.
Sequence of the simulation
With the now known simulation elements, a step chain for the simulation environment can be designed.
- Reading the data
- Establish start conditions
- Process the production program
- Display evaluations
The data for the elements must come from somewhere. So the first step is to read data from a data source. A simulation can only start if it has been determined how this should be done. Therefore, the start conditions are defined in the second step.
In the main part of the simulation, the simulation system processes the virtual production orders. If the entire production program has been processed or if the user cancels it, there must be a possibility to call up evaluations and thus answer the questions of the simulation.
What are the four steps in detail? That is the topic of the next chapters.
Reading the data
The data basis comes from the corporate software, the ERP system. Data storage is usually a relational database system that holds a large number of tables. Data can be exchanged easily if the self-programmed simulation environment also works with a database. Necessary tables are information about articles, workplaces, workplans and the production plan.
| Table | Content |
|---|---|
| Articles | All items used in the simulation with descriptive features |
| Workplaces | All workplaces used with features such as max. daily capacity, order start strategy |
| Workplans | Workplans for each simulation article with their work operations |
| Orders | Production orders of any period with articles and their production quantities |
The simulation system reads this data once into the object structure when the program starts. For performance reasons, it is not a good idea to read data from the database during the simulation.
Depending on the scope of the simulation, therefore, not all available ERP data should be saved, but only those that should be considered for the simulation.
Establish start conditions
In which initial scenario should the simulation begin? There are two answers to this question. On the one hand, it is possible that the simulation should start „empty“. This can be an important question, especially for the investigation of start-up behavior of a line, e. g. to clarify how long it takes for production orders to arrive at downstream workplaces after the start.
On the other hand, startup behavior is rather rare. But there are questions that relate to very specific order constellations.
For example, what happens at workplaces with an order sequence: large lot size – small lot size – large lot size ?
These constellations can also occur after a startup behavior, but simulation time is required for this. It would be better if one could start directly with a defined scenario.
The simulation environment should cope with both situations. In this first version, in the proof of concept, you can only start with an empty simulation.
Process the production program
Once all the data have been read in and the starting conditions have been established, the actual simulation begins. The same thing happens here as in reality.
Each workplace can have an input and / or output buffer. If the input buffer is filled or a production order for the workplace is available, processing can begin.
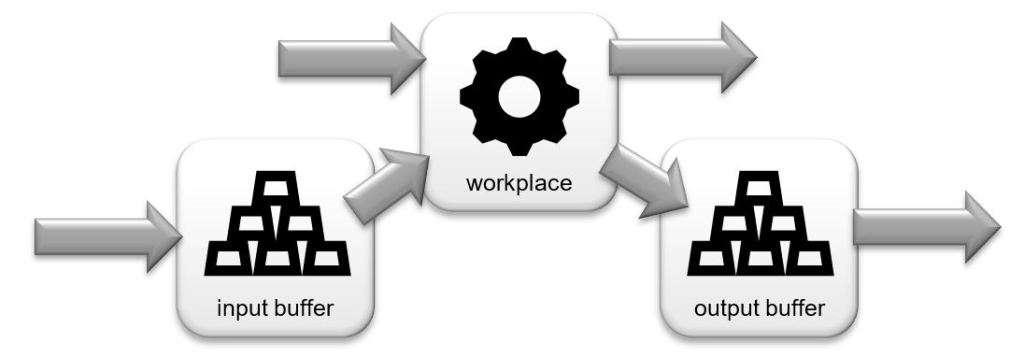
Only one order can be processed at a time. When a production order has been completed, it is passed on to the next workplace via an output buffer, if applicable, and the next production order is removed from the queue. If there is no order, the workplace simply waits.
So there is a lot to control. The simulation control takes over the task. It is repeated in a loop until the production program has run through or the simulation is canceled by the user.
The simulation time is gradually increased in the repetition loop. It checks the production conditions for each workplace in every step.
Each production order is passed on from workplace to workplace until all the work operations contained have been completed.

A work station can have several states.
- Wait – if there is no production order in the queue
- Setup – There is a set-up time in the workplan
- Process – There is a working time in the workplace
In reality there may be other conditions, which are omitted here for reasons of a shorter source code, e. g. by full buffers or workplaces have a fault.
The queues of the input and output buffers work in connection with the workplace as a typical one-station waiting model (single server model). FIFO (first-in-first-out) is used as a strategy: Depending on the order of receipt, the orders are also removed again.
Depending on what the simulation scenario looks like, undesirable constellations can arise from the start state. That controls the source. If a workplace does not have an order in the buffer and there is a suitable one in the source, this is passed on. If a start workplace is also used in intermediate steps, all production orders in the production program are processed according to the FIFO rule.
Display evaluations
Once the simulation is complete, there must be a display of the production status that has been run through.
- Total duration of the simulation
- Lead time of every production order
- Utilization levels of each workplace (wait, setup, process)
- Length of the queue for each job
- Maximum waiting time for the next job
This describes very well what my simple, self-programmed simulation system should do and what the concept of an implementation can look like.
Can you now develop your own simulation system?
I think the question of whether you can program a simple simulation system yourself can be answered with Yes.
I programmed in Lazarus and Freepascal (Object Pascal). Lazarus compiles in fast, native and easy to read code. It is also available for most operating systems. The database is based on Microsoft Access. The connection to Lazarus is made via ODBC. Lazarus offers many options in terms of database technology, so that your database preferences can also be fulfilled. A first look at the software is already possible. You can download and try the runtime version for Windows under Downloads.

You will see, the production program is loaded from the database, workplaces are set up and orders are processed. Orders are routed between workplaces in the order of the workplans.
Now I have to verify whether this is enough to answer the production-related questions.
In terms of learning, I can already draw a conclusion: It helps immensely for the understanding of process flows to look at them from the coding side.
The best way to do this is to understand which relationships are integrated in the object model and how the individual components work together. That would be a bit too much for this blog article, so there is another one. In addition to programming, this also deals with initial results and the verification of the model.
Just have a look at my blog again or enter your email address here. You will then be informed automatically when I publish further articles.
Download

Links
The 7 deadly sins of simulation (according to Liebl):
http://dsor-lectures.upb.de/index.php?id=469
Discrete simulation on Wikipedia:
https://en.wikipedia.org/wiki/Discrete-event_simulation
Lazarus programming environment:
https://www.lazarus-ide.org/
Project page SimProdSim:
https://techpluscode.de/simprodsim-en
Lesen Sie diesen Blog Artikel in Deutsch.








